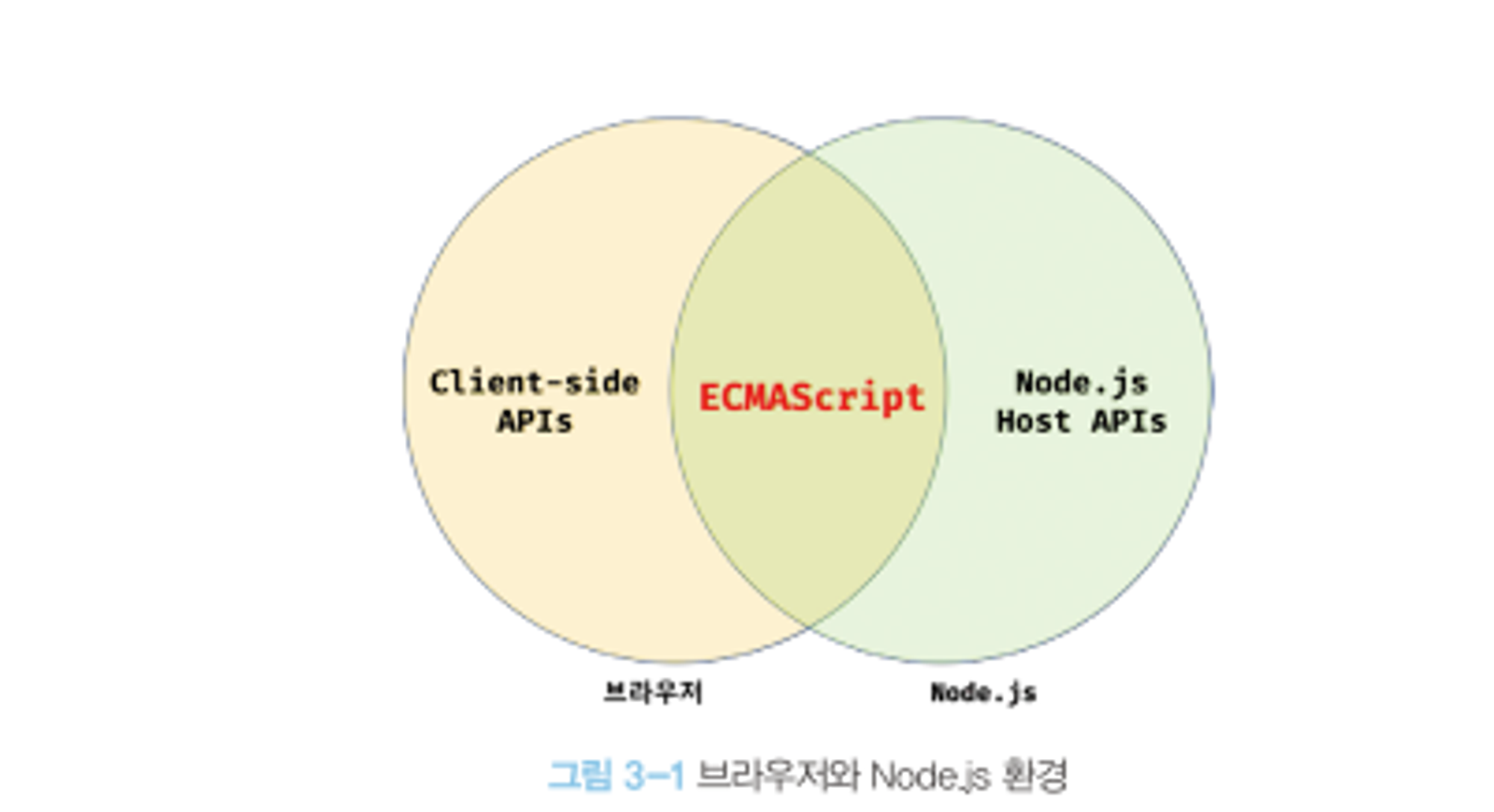
모든 브라우저와 Node.js에서 ECMAScript를 실행할 수 있다. 하지만 ECMAScript 외의 기능들은 호환되지 않는다.
예) 브라우저에서 활용하는 자바스크립트 DOM API
// ECMAScript 코드
const button = document.getElementById('myButton'); // DOM API 사용
// ECMAScript 함수 정의
button.addEventListener('click', () => { // DOM API 사용
alert('Button clicked!'); // ECMAScript 내장 함수 사용
});
Node.js가 DOM API를 활용하지 않는 이유는 Node.js역할과 관련있다. Node.js는 브라우저 외부 환경에서 동작하는 백단의 구현을 위한 실행 환경 이기에 Core 언어로 제공하지 않으며, 필요한 경우 라이브러리를 사용해서 HTML문서를 가공할 수 있다.
백단에서 사용하는 우리가 아는 언어들은 모두 파일 시스템을 기본적으로 제공하는 것처럼 Node.js환경에서는 이를 동일하게 제공한다(Javascript범주). 하지만, 브라우저에서는 이런 파일 시스템을 기본 제공하지 않는다.(FileReader로 읽기동작은 가능)
제공하지 않는 이유 : 브라우저에서 동작하는 자바스크립트가 사용자의 파일을 임의로 다룰 수 있다면 사용자의 파일을 보안 공격으로 쉽게 공격할 수 있음
위에서 이야기한 내용을 정리하면
브라우저
ECMAScript
DOM
BOM
Canvas
XMLHttpRequest
fetch
….
Node.js
ECMAScript
클라이언트 사이드 API(DOM …)를 미지원
Node.js와 NPM
Node.js : 크롬 V8 자바스크립트 엔진으로 빌드된 자바스크립트 런타임 환경 ⇒ 서버 사이드 개발이 가능
NPM(Node Package Manager) : 자바스크립트 패키지 매니저로 Node.js에서 사용할 수 있는 모듈을 패키지화해서 모아둔 저장소 역할, 패키지 설치 및 관리를 위한 CLI를 제공
ES11(2020) → String. prototype. matchAll, BigInt, 옵셔널 체이닝 연산자 등
자바스크립트 성장의 역사
첫 자바스크립트는 웹 페이지의 보조기능을 수행하는 용도였고, 대부분의 로직이 웹 서버에서 실행되며 서버측에서 렌더링(Server Side Rendering)이 진행됨
Ajax
비동기(Asynchronous )방식으로 데이터를 교환할 수 있는 Ajax가 등장하며 렌더링을 Client측에서 직접 렌더링하기 시작했다
서버 측에서의 렌더링은 매번 데이터를 변경할 때마다 새로 페이지를 불러와 렌더링 해야하기에 성능상 문제가 있었고 사용자 입장에서도 좋지않은 경험이였다.
Ajax의 등장으로 변경되는 데이터만 특정하여 값을 변경해 부드러운 화면 전환 효과를 보게 되었다.
jQuery
jQuery는 자바스크립트의 까다롭고 복잡한 문제를 해결해주었고, 직관적인 jQuery로 인해 자바스크립트 환경이 더욱 개선되었다.
V8 자바스크립트 엔진
구글에서 개발한 V8엔진은 빠른 성능을 보여주었고, 데스크톱 애플리케이션과 유사한 사용자 경험을 제공할 수 있게 되었다.
이 이후 클라이언트 사이드 렌더링이 본격적으로 활성화되었고, 프론트엔드 영역이 주목받기 시작했다.
Node.js
브라우저에서만 동작하는 자바스크립트 엔진을 브라우저 이외의 환경에서도 동작할 수 있도록 브라우저에서 독립시킨 자바스크립트 실행 환경
Node.js가 생기며 프론트, 백 모두 자바스크립트를 사용해 개발할 수 있다는 동형성(동일한환경)이라는 *_장점이 있으며, *_비동기I/O, 단일스레드 이벤트 루프 기반으로 동작하기에 요청 처리성능이 좋으며 실시간으로 데이터를 처리하기 위해 I/O가 빈번하게 발생하는 SPA(Single Page Application)에 적합하다.
SPA 프레임워크
복잡해진 개발환경에서는 이전의 자바스크립트 환경에서는 수행하긴 하지만 변경에 유연해지며 CBD 방법론을 기반으로 하는 SPA(Single Page Application)가 대중화되었다.
SPA를 돕는 프레임워크/라이브러리로는 Angular, Reach, Vue.js, Svelte 등이 있다
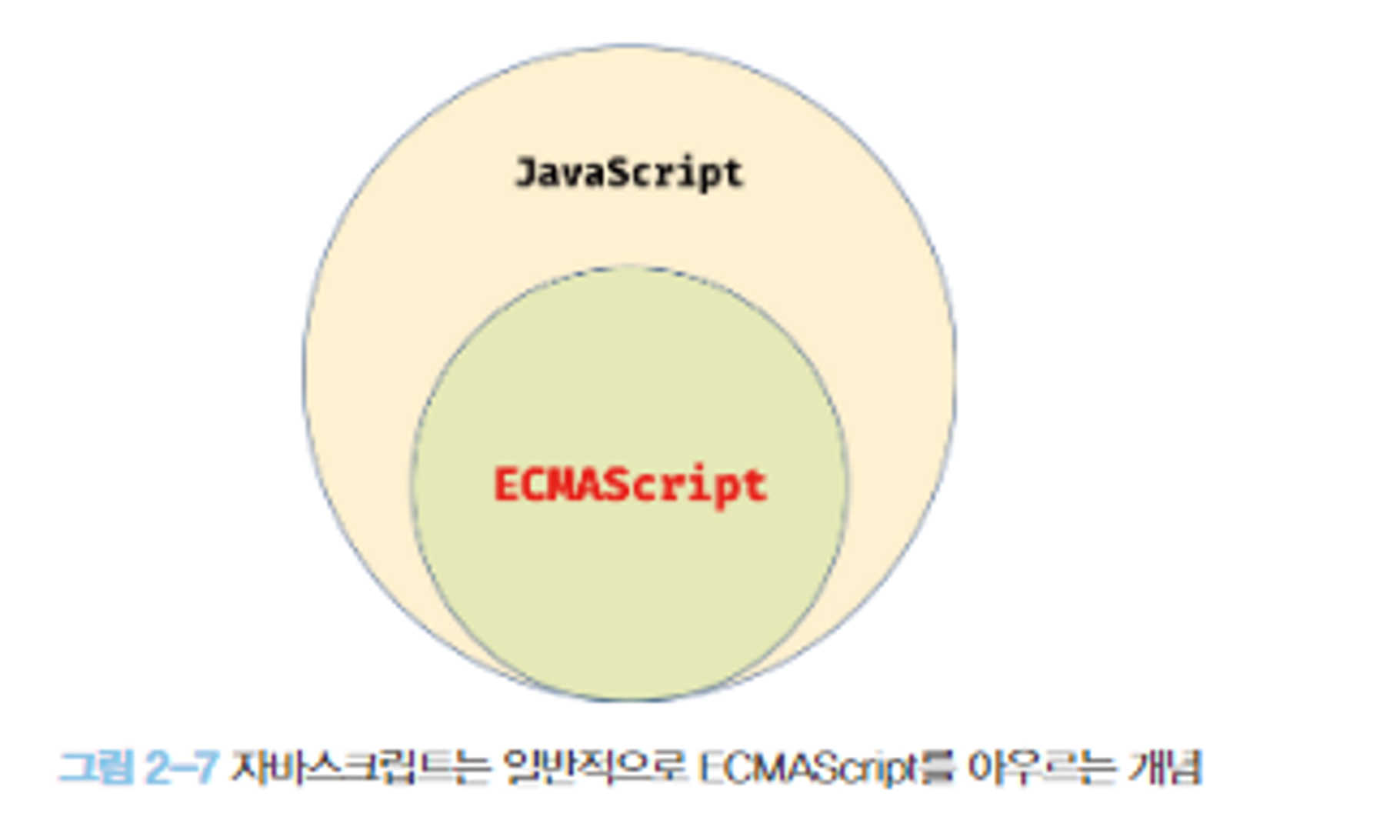
자바스크립트와 ECMAScript
각 브라우저 제조사는 ECMAScript 사양을 준수해서 브라우저에 내장되는 자바스크립트 엔진을 구현한다.
자바스크립트는 큰 범주로 JavaScript내에 ECMAScript가 들어있다.
ECMAScript는 자바스크립트에서 구현할 때의 뼈대라고 생각해야 한다. 이 뼈대는 문법과 기본 기능을 정의하며 ECMAScript를 기반으로 브라우저에서 자바스크립트가 동작하는 엔진을 구현하여 자바스크립트 실행 환경을 제공한다.
자바스크립트는 브라우저 엔진을 통해 만들어져 실제 웹 페이지와 상호작용하기 위해 사용되는 프로그래밍 언어이다.
자바스크립트의 특징
웹 브라우저에서 동작하는 유일한 프로그래밍 언어이다.
개발자가 별도의 컴파일 작업을 수행하지 않는 인터프리터 언어이다.
인터프리터 언어의 단점인 실행시간을 최적화하기 위해 JIT(Just-In-Time) 컴파일 기술이 도입되어 자주 실행되는 코드를 컴파일해둔다
명령형, 함수형, 프로토타입 기반 객체지향 프로그래밍을 지원하는 멀티 패러다임 프로그래밍 언어이다.
스터디 회고
자바스크립트가 ECMAScript를 아우른다는 것 추가설명
이 부분이 다음 주 주제와도 연결이 되다보니 이해가 중요한 부분이였는데, 제가 설명을 자세히 못 적었다고 생각이 드네요..!
다음번엔 이해하기 쉽도록 더 잘 정리해보겠습니다 ㅜㅜ
제가 이해할 때 도움됐던 부분을 조금 더 정보를 꺼내 부연 설명 드리자면, 크롬의 경우 우리가 자주 사용하는 확장프로그램을 예시로 들 수 있습니다.
확장프로그램은 ECMAScript 표준을 기반으로 작성되며, 브라우저 자체에서 제공하는 고유API와 모듈을 사용해 다른 기능과 상호작용합니다.
크롬 자체에서만 지원하는 API를 활용하기에 이는 JavaScript 라고 이해했었습니다!
if (request.message === 'Tab updated') {
console.log('Tab was updated');
}
});
🤔 질문
자바스크립트에 대해 알게 된 좋은 글이었습니다! 감사합니다
올려주신 글 부분에서 Node.js 설명 중 궁금한 부분이 있습니다. Node.js에서 단일 스레드 이벤트 루프 기반이라는데, 단일 스레드인 경우에는 여러 요청들이 몰리면 성능에 이슈가 생기는 것은 아닌가요? 단일 스레드라 요청 처리 성능이 좋다고 되어 있어서 궁금해져 여쭤봅니다!..
🖥️ 답변
저도 처음에 보고 당황해서 따로 검색을 했었는데, 명확히 이해하지 못했다 생각해 올리지는 않았었습니다..
제가 이해가 가능했던 부분까지 설명을 해보자면, 이벤트 루프에 대한 이해가 필요한데요.
간단하게 한 문장으로 표현하자면, 싱글스레드로 이벤트 루프 기능이 동작하고 있고, 상세 기능은 내부적으로 비동기요청들을 멀티스레드 처리생성해 로직 처리 후 콜백하는 형태입니다.
노드에서는 멀티스레드 처리하는 라이브러리를 libuv라고 부르며, 이 라이브러리가 스레드풀에 멀티스레드를 담은 후 요청들에 대한 처리를 진행 한다고 합니다.
때문에 싱글 스레드로 동작을 모니터링 후 동작 처리는 멀티스레드 라이브러리(libuv)에 비동기 요청으로 맡기는 식으로 동작한다고 합니다.
저도 완전한 이해를 기반으로 답변드리지 못하여 아쉽지만 생각보다 단번에 이해하기 어려워 큰 틀에서만 이해해둔 상태입니다..!
우리가 알고있는 HTTP통신은 OSI 7계층의 응용계층에 속한다. 이 통신을 하기 위해 어떤 동작이 이루어지는지 키워드를 갖고 간단하게 다뤄보자
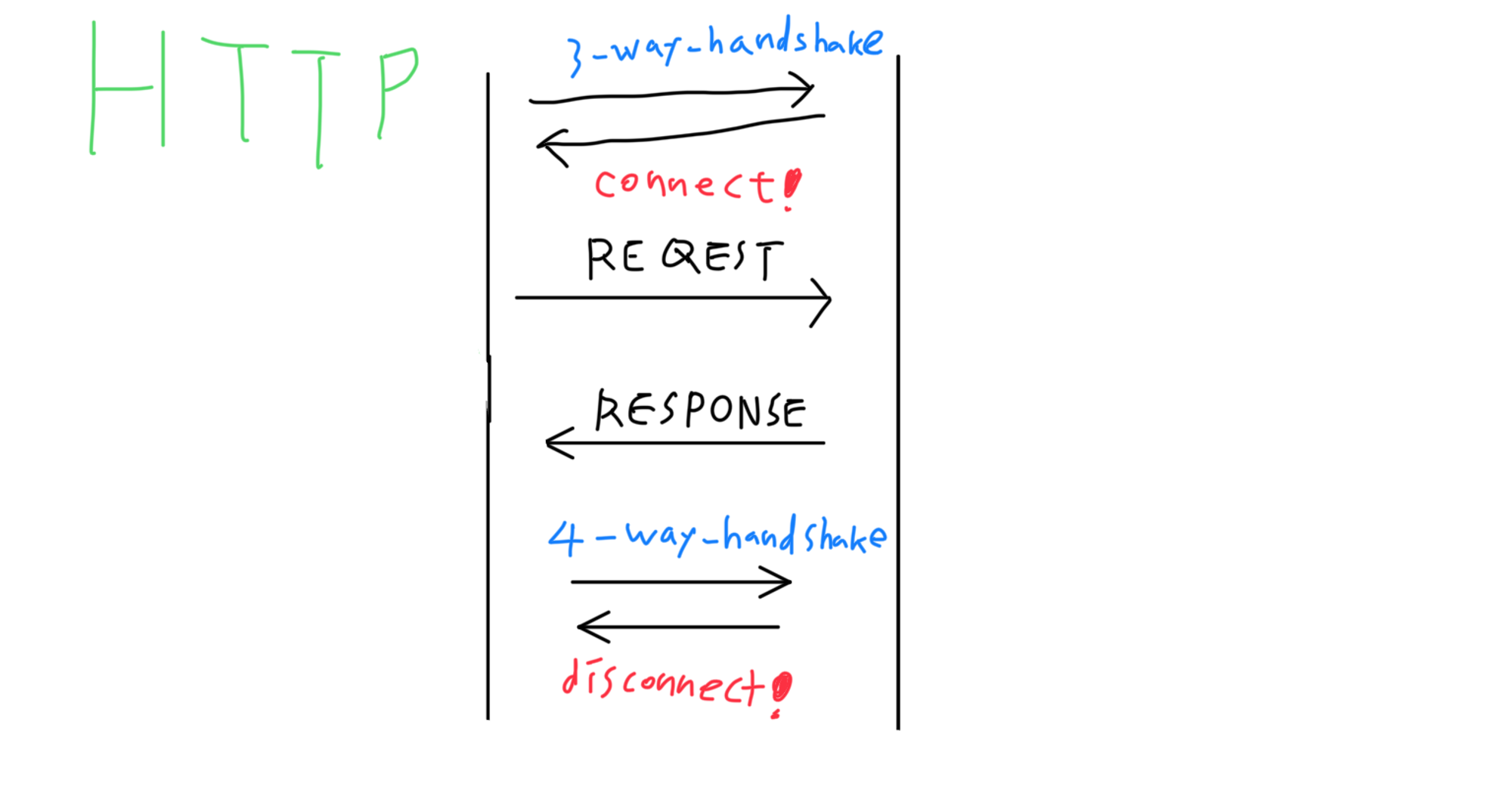
TCP(Transmission Controll Protocol)
TCP는 클라이언트와 서버간의 데이터 통신을 위해 사용하는 4계층에 속하는 프로토콜이다. HTTP는 기본적으로 통신을 하기 위해 TCP를 활용해 3-way-handshake 과정을 거쳐 TCP 소켓 연결을 하고 데이터를 전송한다.이후 소켓 연결을 해제할 때는 4-way-handshake 과정을 거쳐 연결을 해제한다.
3-way-handshake
TCP통신은 기본적으로 3방향 핸드셰이크라는 방식으로 네트워크 소켓연결을 시도하는데 SYN → SYN-ACK → ACK 의 순서로 진행된다.
소켓연결 후 소켓을 끊을 때는 4-way-handshake 과정을 진행한다. 여기서 사용하는 주요 FLAG는 FIN, ACK이 있다.
해당 연결해제 절차는 클라이언트 측과 서버 측 모두 사용 가능하기에 A, B로 설명하자면,
A(FIN) → B
B(ACK) → A
B(FIN) → A
A(ACK) → B
위의 순서를 통해 A와 B의 소켓이 해제되는데 최초 (1)FIN요청을 받은 B는 A에게 (2)ACK신호를 줌과 동시에 연결을 끊는 작업을 시행하고 연결을 종료할 수 있는 준비작업이 완료되면 B가 A에게 최종종료되었다는 (3)FIN FLAG를 넘겨준다. 이를 받은 A는 최종확인 (4)ACK FLAG를 B에게 보냄으로써 소켓은 서로 닫히게 된다.
HTTP 통신
HTTP통신으로 호출하기 위한 흐름은 기본적으로 TCP 소켓 연결을 기본으로 소켓연결이 된 후 Request & Response작업이 진행된다.
때문에 순서를 다시한번 적자면 이렇게 된다
3-way-handshake → Request → Response → 4-way-handshake의 순서로 통신 흐름을 이해할 수 있다.
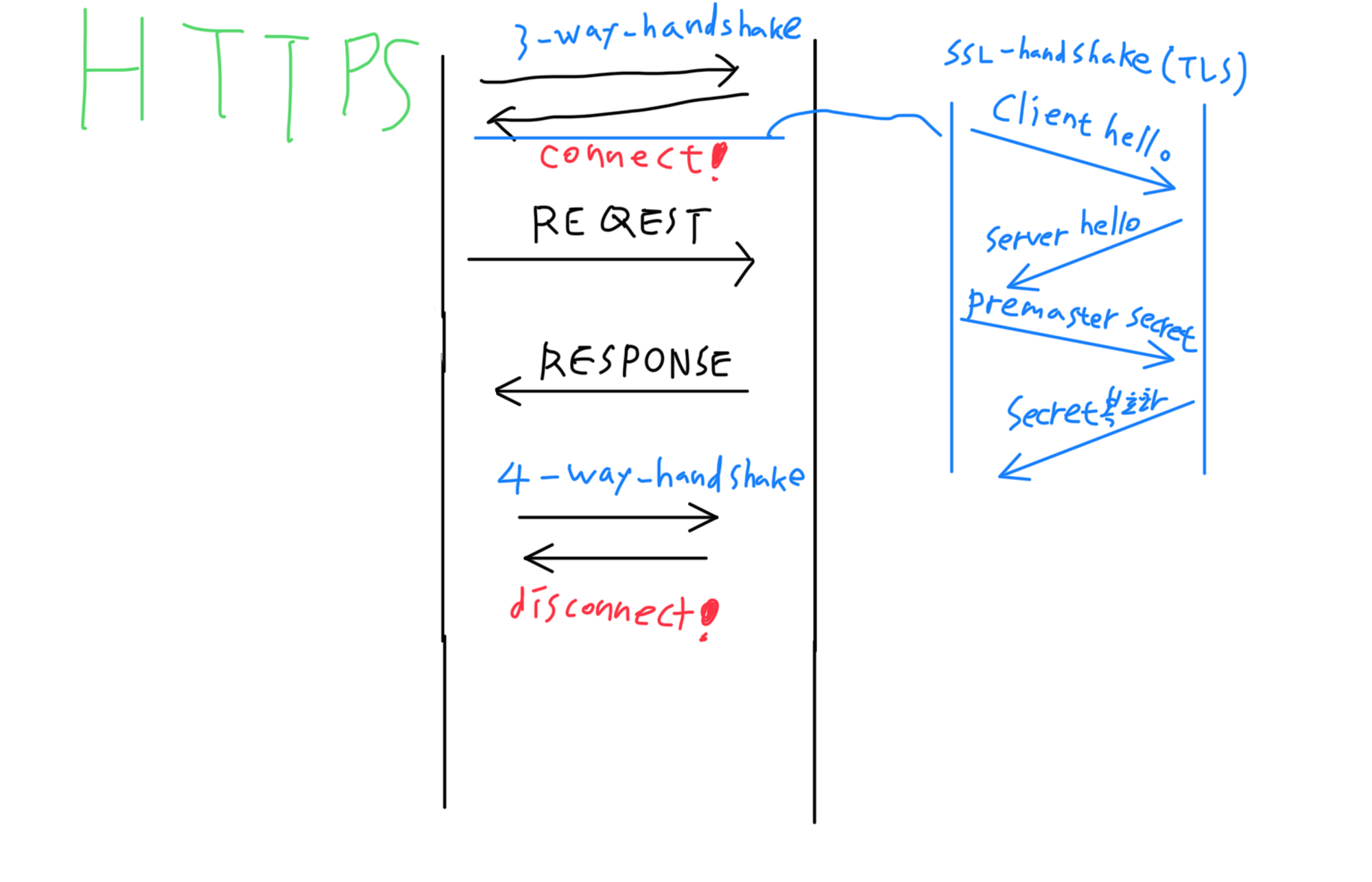
HTTPS 통신
우리가 평소에 사용하는 사이트들은 모두 HTTP가 아닌 HTTPS를 사용하고있다. HTTPS는 Http에 S(Secure)가 붙어서 보안을 강화시킨 통신방식인데, 이 통신을 시행하면 중간에 데이터를 가로채가도 데이터는 암호화되어있기에 어떤 데이터를 가로챈건지 알 수 없게 되는 보안프로토콜이다.
이 통신방식은 Secure Sockets Layer(SSL)/Transport Layer Security (TLS) 등으로 불리우는 암호화 프로토콜통신(SSL Handshake, TLS Negotiation)을 HTTP통신의 데이터 교환에 앞서서 시행한다.
SSL Handshake, TLS Negotiation
이 통신을 SSL Handshake/TLS Negotiation이라고도 불리며, 기존의 소켓연결인 3-way-handshake 직후에 시행하는 통신작업인데, 순서는 다음과 같다.
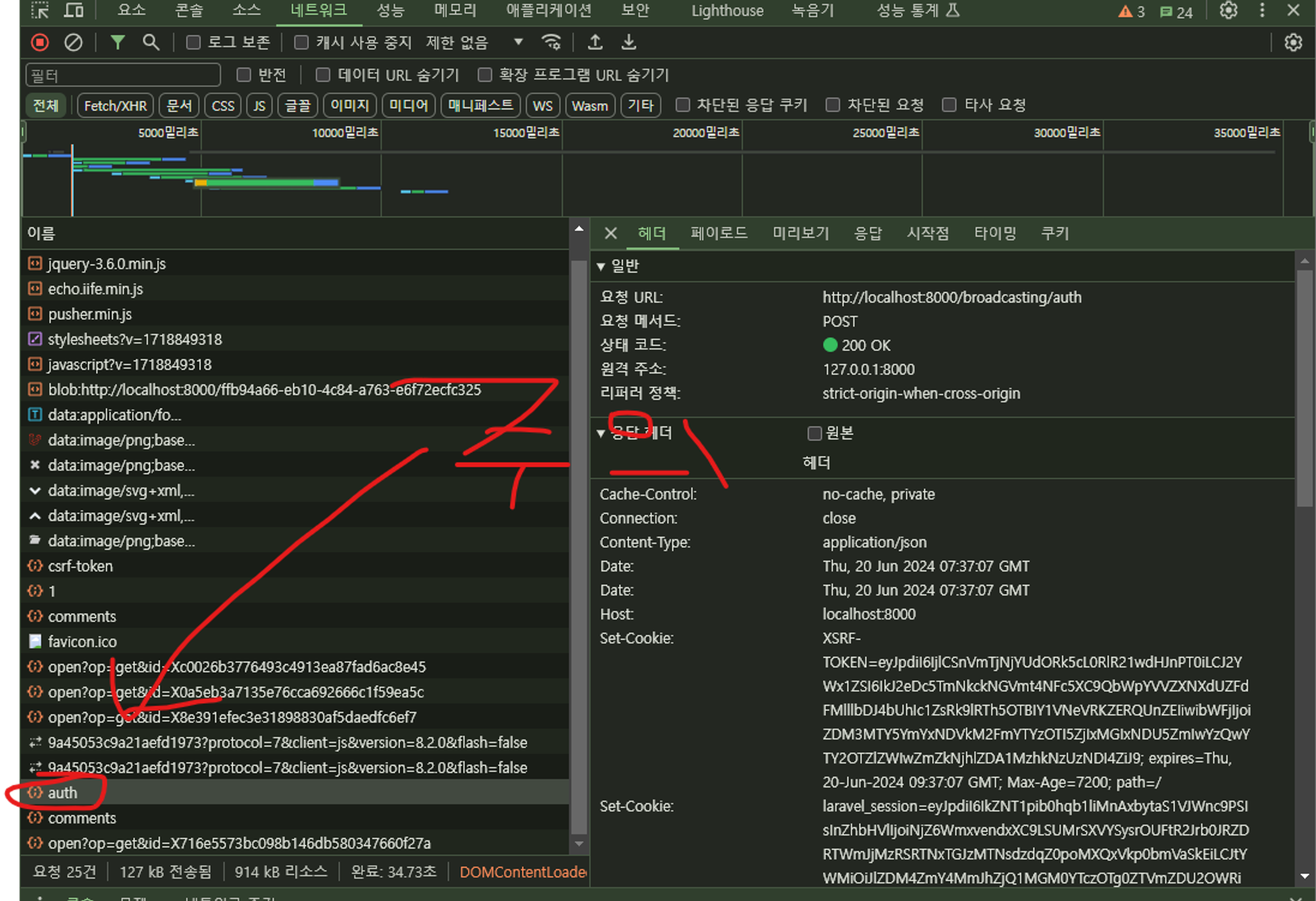
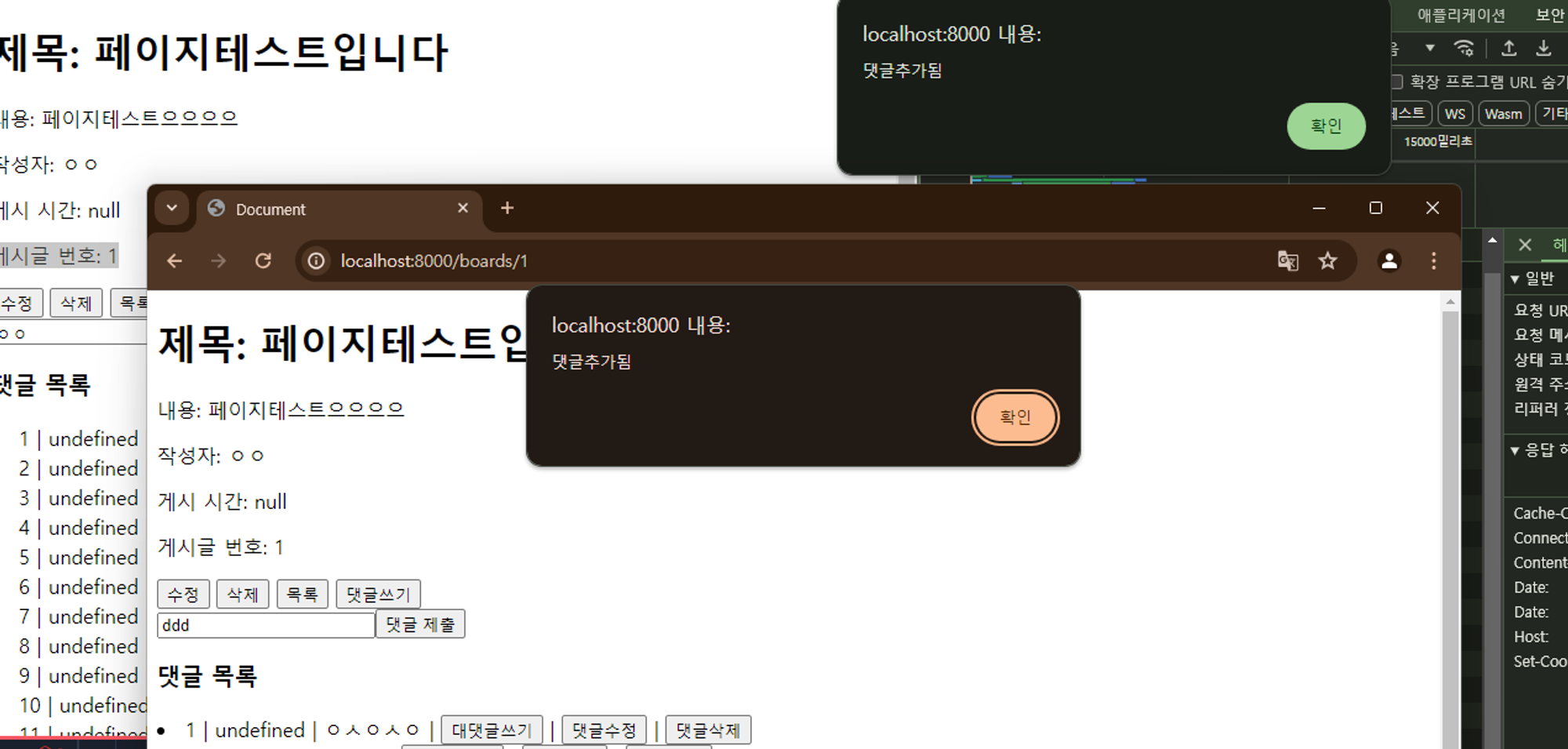
Broadcast::channel('comment.{boardId}', function ($user, $boardId) {
// 게시판의 모든 사용자가 이 채널을 들을 수 있도록 설정
$board = \\App\\Models\\Board::find($boardId);
if (!$board) return false;
// 이 예제는 간단하게 모든 사용자에게 접근을 허용합니다.
return true;
});
구독채널 설정
Events/CommentPosted.php
<?php
namespace App\\Events;
use Illuminate\\Broadcasting\\Channel;
use Illuminate\\Queue\\SerializesModels;
use Illuminate\\Broadcasting\\PrivateChannel;
use Illuminate\\Broadcasting\\PresenceChannel;
use Illuminate\\Foundation\\Events\\Dispatchable;
use Illuminate\\Broadcasting\\InteractsWithSockets;
use Illuminate\\Contracts\\Broadcasting\\ShouldBroadcast;
use App\\Models\\Comment;
class CommentPosted implements ShouldBroadcast
{
use Dispatchable, InteractsWithSockets, SerializesModels;
public $comment;
public function __construct(Comment $comment)
{
$this->comment = $comment;
}
public function broadcastOn()
{
return new PrivateChannel('comment.' . $this->comment->board_id);
}
}
ShouldBroadcast를 상속받은 구현체를 만들어서 채널명과 구독방식 등을 정해둘 수 있다.
SELECT FOOD_TYPE, REST_ID, REST_NAME, MAX(FAVORITES)
FROM REST_INFO
GROUP BY FOOD_TYPE
ORDER BY FOOD_TYPE DESC;
정답
SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
FROM REST_INFO
WHERE (FOOD_TYPE, FAVORITES) IN
(SELECT FOOD_TYPE, MAX(FAVORITES)
FROM REST_INFO
GROUP BY FOOD_TYPE)
ORDER BY FOOD_TYPE DESC
public class Audience{
public Bag bag;
->
private Bag bag;
public Bag getBag() {
return bag;
}
->
public Long buy(Ticket ticket){
if( bag.hasInvitation()) {
bag.setTicket(ticket);
return 0L;
} else {
bag.setTicket(ticket);
bag.minusAmount(ticket.getFee());
return ticket.getFee();
}
}
변화점 : 각 객체들이 맡은 책임에 맞게 일을 행하도록 구현되었다.
Theater의 경우를 예로 들었을 때 객체는 다른 객체에게 이 일을 행해달라고 전달했을 뿐이다.
캡슐화와 응집도
객체지향의 핵심은 객체 내부의 상태를 캡슐화하고 객체 간에 오직 공용 인터페이스(메시지)를 통해서만 상호작용하도록 만드는 것
객체가 밀접하게 연관된 작업만을 수행하고 연관성이 없는 작업은 다른 객체에게 위임하는 것이 응집도를 높이는 방법이다.
자신의 데이터를 책임지며 자신의 데이터를 가공하는 것이 객체의 응집도를 높이는 핵심
절차지향과 객체지향
절차적 프로그래밍 Step01에서는 Theater가 절차지향적인 코드였으며, Process역할을 했었다. 이렇게 Step01의 Theater처럼 별도 모듈에 위치시키는 방식
객체지향 프로그래밍 Step02에서는 프로세스가 각 객체 안에서 동작하도록 구성했다. ex)class Audience
책임의 이동(shift of responsibility) 두 방식의 근본적인 차이는 기능을 처리할 때 Theater가 직접 처리를 하는 방식과, Theater가 말을하면 Audience와 TicketSeller가 스스로 처리를 하는 방식으로 구분을 할 수 있다.
책임 집중 : Theater
책임 분산 : buy → Audience, SellTo → TicketSeller
Step03. 추가 개선
TicketOffice
기존 : getTicket, getFee를 통해 티켓 자체를 Office에서 꺼내옴
변경 : sellTicketTo를 통해 기존의 티켓을 꺼내오는 방식 변경
class TicketOffice{
...
public Ticket getTicket(){
...
}
public void plusAmount(){
...
}
...
}
->
class TicketOffice{
...
public void sellTicketTo(Audience audience){
plusAmount(audience.buy(getTicket()));
}
private Ticket getTicket(){
...
}
private void plusAmount(){
...
}
...
}
public TicketOffice getTicketOffice() {
return ticketOffice;
}
->
public class TicketSeller{
public void sellTo(Audience audience){
ticketOffice.sellTicketTo(audience);
}
}
인터페이스에만 의존하게하는 형태로 변경됨
but TicketSeller는 audience를 넘겨주며 서로 의존하게 만듦
트레이드오프
인터페이스에만 의존하는 Audience결합도가 중요한지, audience를 넘겨주며 의존성이 생겨난 것이 더 좋을지 개발자는 트레이드 오프를 해야 할 순간이 온다.
두가지 이슈를 통해 (책에서의)개발팀은 TicketOffice의 자율성을 지켜 의존성 제거를 택했다.
의인화
Theater, Bag, TicketOffice는 실세계에서 자율적인 존재가 아니다. 하지만 객체지향 패러다임에서는 생물과 동일하게 객체로 다뤘다. 이렇게 모든 객체는 능동적이고 자율적인 존재로 바뀌도록 설계하는 원칙을 의인화라고 부른다
자바 7 이전의 버전에서는 병렬의 처리가 어려웠다. 분할을 위한 스레드 할당 → 동기화 추가 → 결과 합치기의 과정을 통해 병렬 처리가 실행되는데, 각 병렬처리를 한 후에 스레드를 합칠 때 동기화를 적절히 이뤄줘야 교착 상태를 피할 수 있었다. 7버전 부터 지원하기 시작한 Fork/Join 프레임워크를 활용하면 해당 문제를 쉽고 효율적으로 해결할 수 있다. 이 Fork/Join 프레임워크를 활용한 스트림 API와 병렬 처리에 대해서 배워보자.
병렬 스트림
각각의 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림
멀티코어 프로세서가 각각의 청크를 처리하도록 한다
Collections.parallelStream() or Arrays.stream().parallel()
Pipeline에있는 parallel 상태에 true가 저장된다.
이후 파이프라인 처리할 때 처리할 때 parallel 체크를 통해 해결한다.
병렬 처리를 고려할 때는 성능 벤치마킹을 하는 것을 권장
성능 최적화
기본형(primitive) 타입의 경우 기본형 특화 스트림 권장 - 오토박싱의 이유
일반적으로 순차적인 처리가 필요한 스트림의 경우 병렬 비용이 더욱 비싸 느릴 가능성이 높음
순차 처리가 필요없는 경우 findAny같은 순서에 상관 없는 쇼트 서킷, unordered 같은 메서드 사용
하나의 요소를 처리하는 데 드는 비용이 비싸다면 고려
스트림 자료구조의 특성을 확인 ex) LinkedList vs ArrayList 일반적으로 좋음
병합 과정의 비용을 생각해야 한다
| 소스 | 분해성 |
| --- | --- |
| ArrayList | Excellent |
| LinkedList | Bad |
| IntStream.range | Excellent |
| Stream.iterate | Bad |
| HashSet | Good |
| TreeSet | Good |
| Stream.generate | iterate보단 낫다 |
parallel처리 관련 이미지
포크/조인 프레임워크
병렬 작업할 때 사용
재귀적으로 큰 작업을 작은 작업으로 분할한 후 서브태스크의 결과를 합쳐서 전체 결과를 만듦
스레드 풀(ForkJoinPool)의 작업자 스레드에 분산 할당하는 ExecutorService
ExecutorService를 왜 언급하는가?
RecursiveTask를 실제로 활용했을 때 해당 추상 클래스의 부모인 ForkJoinTask에서 ForkJoinPool을 활용해서 실제 활용하고있기 때문
RecursiveTask → ForkJoinTask에서 사용하는 ForkJoinPool → ExcutorService
분할 정복(divide-and-conquer) 알고리즘의 병렬화
compute() 메서드 오버라이딩 해서 구현
병렬처리 시 주의점
join 호출은 두 서브태스크가 모두 시작된 다음에 해야한다.
ForkJoinPool의 invoke메서드는 병렬 계산 시작하는 시점에서 한번만 사용
한쪽은 fork() 한쪽은 compute() ⇒ 같은 스레드 재사용 피하기 위함
디버깅이 어렵다 ⇒ 스택이 아닌 다른 스레드 이기 때문
병렬 처리가 무조건 빠르지 않다.
작업 훔치기(work stealing) 특성을 갖고있음
ForkJoin을 활용한 RecursiveTask 예시
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
public class ForkJoinSumCalculator extends RecursiveTask<Long> {
//THRESHOLD 이상의 값 까지만 분해
public static final long THRESHOLD = 10_000;
private final long[] numbers;
private final int start;
private final int end;
public ForkJoinSumCalculator(long[] numbers) {
this(numbers, 0, numbers.length);
}
private ForkJoinSumCalculator(long[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
int length = end - start; //해당 태스크에서 더할 배열의 길이
if (length <= THRESHOLD) {
return computeSequentially();
}
//각 태스크 분리 left, right
ForkJoinSumCalculator leftTask =
new ForkJoinSumCalculator(numbers, start, start + length / 2);
//생성한 태스크 비동기 실행
leftTask.fork();
ForkJoinSumCalculator rightTask =
new ForkJoinSumCalculator(numbers, start + length / 2, end);
//두번째 태스크 동기 실행
Long rightResult = rightTask.compute();
//비동기 실행했던 left의 결과를 읽거나 처리완료 후 읽기까지 대기
Long leftResult = leftTask.join();
return leftResult + rightResult;
}
//가장 작은 단위일 때 작은 단위로 쪼갠 태스크의 결과를 계산
private long computeSequentially() {
long sum = 0;
for (int i = start; i < end; i++) {
sum += numbers[i];
}
return sum;
}
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return FORK_JOIN_POOL.invoke(task);
}
}
//호출 방법
ForkJoinSumCalculator.forkJoinSum(long n));
Spliterator 인터페이스
구성 요소
booleaen tryAdvance(Consumer<? super T> action)
요소를 하나씩 순차적으로 돌며 요소가 남아있는지 확인
Spliterator trySplit()
일부 요소를 분할해서 새로운 Spliterator 생성
long estimateSize()
탐색해야 할 요소 수 정보 제공(RecursiveTask의 THRESHOLD 역할로 보임)