Chapter06 스트림으로 데이터 수집
6장에 들어가며..
이번 장의 초점은 최종 연산인 collect에 맞춰져 있다.
맛보기 - 통화별로 트랜잭션을 그룹화한 코드
<명령형 프로그래밍>
Map<Currency, List<Transaction>> transactionsByCurrencies = new HashMap<>();
for(Transaction transaction : transactions) {
Currency currency = transaction.getCurrency();
List<Transaction> transactionsForCurrency = transactionsByCurrencies.get(currency);
if(transactionsForCurrency == null){
transactionsForCurrency = new ArrayList<>();
transactionsByCurrencies.put(currency, transactionsForCurrency);
}
transactionsForCurrency.add(transaction);
}
->
<함수형 프로그래밍>
Map<Currency, List<Transaction>> transactionsByCurrencies =
transactions.stream().collect(Collectors.groupingBy(Transaction::getCurrency));
collect메서드를 통해 Collector 인터페이스를 사용하는데, groupingBy를 이용해서 각 키 버킷, 키 버킷에 대응하는 요소 리스트를 값으로 포함하는 맵이 만들어지게 된다.
Collect
- 스트림에서 지원하는 메서드
- collect(리듀싱)
- collect(Collector인터페이스 사용)
Collector
- 인터페이스
- 리듀싱 연산이 수행
- 스트림의 요소를 어떤 식으로 도출할지 지정
Collectors
- 유틸리티 클래스
- 정적 팩토리 메서드
- 기능
- 스트림 요소를 하나의 값으로 리듀스하고 요약
- 요소 그룹화
- 요소 분할
리듀싱과 요약
스트림.collect를 통해 스트림의 모든 항목을 하나의 결과로 합칠 수 있다.
Collectors.maxBy, minBy - 스트림 값에서 최댓값과 최솟값 검색
Comparator<Dish> dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories);
Optional<Dish> mostCalorieDish =
menu.stream()
.collect(
Collectors.maxBy(dishCaloriesComparator)
);
- Optional반환
- 객체의 숫자 필드의 합계나 평균 연산 ⇒ 요약 연산
요약 연산
- Collectors.summingInt, double, long
- averagingInt, double, long
- summarizingInt
- count, sum, min, average, max
- getter
IntSummaryStatistics menuStatistics = menu.stream()
.collect(
Collectors.summarizingInt(Dish::getCalories)
);
Collectors.joining - 문자열 연결
- 각 객체에 toString메서드를 호출해서 모든 문자열을 하나의 문자열로 연결해서 반환
- StringBuilder가 활용됨
Collectors.reducing - 범용 리듀싱 요약 연산
- 모든 컬렉터는 reducing 팩토리 메서드로도 정의가 가능하다. 하지만, reducing이 아닌, 다른 팩토리 메서드를 사용하는 이유는 편의성 때문이다.
<인수가 3개인 reducing>
int totalCalories = menu.stream()
.collect(Collectors.reducing(
0, Dish::getCalories, (i, j) -> i + j)
);
<인수가 1개인 reducing>
Optional<Dish> mostCalorieDish = menu.stream()
.collect(Collectors.reducing(
(d1, d2) ->
d1.getCalories() > d2.getCalories() ? d1 : d2)
);
- reducing에 들어가는 인수 3개
- seed(identity)
- mapper(Function)
- BinaryOperator
- reducing에 들어가는 인수 1개
- Optional반환 → 최소 2개 이상의 값이 필요하기 때문에
- 첫번째 스트림 요소 = seed(identity)
- 두번째 요소부터 BinaryOperator(seed, nextStream)
collect vs reduce
collect는 위에서 설명했던 것처럼 스트림의 요소를 어떤 식으로 도출할지 지정하는 특성을 갖고 있다. 즉 도출하려는 결과를 누적하는 컨테이너를 바꾸도록 설계되어 있는 가변형 메서드인 반면에 reduce는두 값을 하나로 도출하는 불변형 연산 이라는 점에서 의미론 적인 문제가 일어난다. 또 7장에서 다루는 병렬 처리 관련해서도 문제가 발생할 수 있다.
컬렉션 프레임워크 유연성 : 같은 연산도 다양한 방식으로 수행할 수 있다.
but 위에서 말했던 collect와 reduce처럼 용도에 맞는 형식으로 최대한 구현하는 것을 권장한다.
자신의 상황에 맞는 최적의 해법 선택
위에서 말했듯 컬렉션 프레임워크의 유연성 때문에 다양한 방식으로 동일한 결과를 낼 수 있지만, 방법에 따라 성능의 차이나 가독성의 문제가 생길 수 있다. 예를들면 reduce연산을 통해 누적 값을 검색하는 것이 아니라 mapToInt를 통해 IntStream으로 변환 후 .sum을 한다면 언박싱을 할 필요가 없어지므로 성능 향상을 볼 수 있을 것이다.
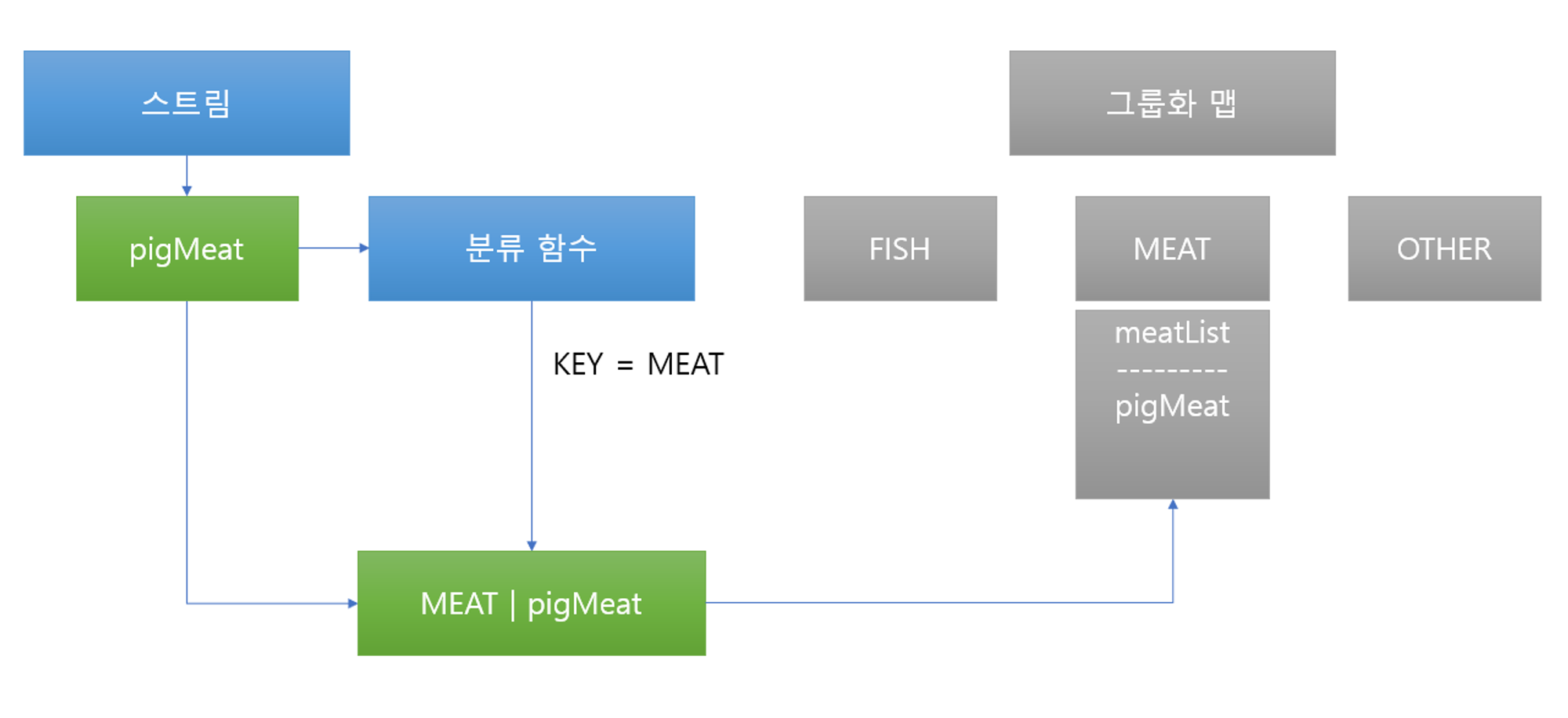
Collectors.groupingBy - 그룹화
<Type 기준으로 분류>
Map<Dish.Type, List<Dish>> dishesByType = menu.stream()
.collect(Collectors.groupingBy(Dish::getType));
<조건 기준 분류>
public enum CaloricLevel { DIET, NORMAL, FAT }
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel =
menu.stream()
.collect(
groupingBy( dish -> {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}));
- Dish.Type.values()을 통해 키값이 생성된다고 생각하면 되고, 이를 분류 함수(classification function)라고 부른다.
- 각 키를 기준으로 분류를 할 수 있다.
- 위의 값들을 기준으로 좀 더 명확히 하기 위해 설명하자면
List리스트에 있는 Dish::getType을 통해 Map<K, V>가 설정되며, K가 Dish::getType의 반환타입, V는 해당 객체 자체를 List에 담아 저장하는 것을 의미한다.
그룹화된 요소 조작
Collectors.filtering
Map<Dish.Type, List<Dish>> caloricDishesByType =
menu.stream()
.collect(groupingBy(Dish::getType,
Collectors.filtering(dish -> dish.getCalories() > 500, toList())));
Collectors.mapping
Map<Dish.Type, List<Dish>> caloricDishesByType =
menu.stream()
.collect(groupingBy(Dish::getType, mapping(Dish:getName, toList())));
Collectors.flatMapping
Map<Dish.Type, List<Dish>> caloricDishesByType =
menu.stream()
.collect(groupingBy(
Dish::getType,
flatMapping(dish -> dishTags.get(dish.getName()).stream,
toSet())));
컬렉터 결과를 다른 형식에 적용하기
Optional같은 반환타입이 들어왔을 때 해당 값이 있다는 것을 보장한다면 고려할 수 있는 방법
.collect(groupingBy(Dish::getType, -> 분류함수
collectingAndThen(maxBy(comparingInt(Dish::getCalories)), -> 컬렉터래핑
Optional::Get))); -> 변환함수
컬렉션 형식을 바꾸는 방법
toCollection(HashSet::new); → TreeSet등 변환이 가능
partitioningBy - 분할
- 분할은 특수한 종류의 그룹화
- 분할은 분할 함수(partitioning function)라 불리는 프레디케이트
- 맵의 키 형식은 Boolean
- 한개의 인수를 받을 때
- 두개의 인수를 받을 때
- 다중 맵으로 필터링할 수 있음
Map<Boolean, Map<Dish.Type, List<Dish>>> vegetarianDishesByType =
menu.stream()
.collect(partitioningBy(
Dish::isVegetarian, ->true false
groupingBy(Dish::getType)->Type별로 또 나눔
));
분할의 장점
- 참, 거짓 두 가지 요소의 스트림 리스트를 모두 유지하는 것이 장점
- 때문에 분류 목록을 만들 때 활용하기 좋다
Collector 인터페이스
Collector 인터페이스는 리듀싱 연산을 어떻게 구현할지 제공하는 메서드 집합으로 구성된다.
Collector<T, A, R> 인터페이스의 시그니처
- T는 수집될 스트림 항목의 제네릭
- A는 누적자, 중간 결과를 누적하는 객체
- R은 수집 연산 결과 객체의 형식
Collector 인터페이스의 메서드
Supplier<A> supplier()
- 새로운 결과 컨테이너 만들기
- 빈 누적자(seed) 인스턴스 만들기
- ex) return () → new ArrayList();
BiConsumer<A, T> accumulator()
- 결과 컨테이너에 요소 추가하기
- 리듀싱 연산을 수행하는 함수를 반환
- n번째 요소를 탐색할 때 두 인수, 누적자와 n번째 요소를 함수에 적용한다.
- A → 누적자 T를 A에 반영한 후 반환
- ex)
return List::add; or return (list, item) → list.add(item);
Function<A, R> finisher()
- 최종 변환값을 결과 컨테이너로 적용하기
- 누적자 객체를 최종 결과로 변환
BinaryOperator<A> combiner()
- 두 결과 컨테이너 병합
- 병렬 처리된 누적자를 결합하는 메서드
SET<Characteristics> characteristics()
- collect 메서드가 어떤 최적화(ex : 병렬화)를 이용해서 리듀싱 연산을 수행할 것인지 결정하도록 돕는 힌트
- Characteristics은 각 특성을 담고있는 Enum 을 넣어서 힌트를 제공.
- UNORDERED - 방문 순서나 누적 순서에 영향을 받지 않는다.
- CONCURRENT - 다중 스레드에서 accumulator 함수를 동시에 호출할 수 있으며 병렬 리듀싱이 수행 가능하다.
- IDENTITY_FINISH - 리듀싱 과정의 최종 결과에 누적자 객체를 바로 사용할 수 있는 것
응용하기
직접 List를 담는 ToListCollector를 구현해보자
//<version1 직접 interface 구현체 만들기>
import java.util.*;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
public class ToListCollectorTest<T> implements Collector<T, List<T>, List<T>> {
@Override
public Supplier<List<T>> supplier() {
return ArrayList::new;
}
@Override
public BiConsumer<List<T>, T> accumulator() {
return List::add;
}
@Override
public BinaryOperator<List<T>> combiner() {
return (list1, list2) -> {
list1.addAll(list2);
return list1;
};
}
@Override
public Function<List<T>, List<T>> finisher() {
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH, Characteristics.CONCURRENT));
}
}
-----------------------------------------
//<version2 간단한 리듀싱은 구현체 필요없음>
List<Dish> dishes = menuStream.collect(
ArrayList::new,
List::add,
List::addAll
);
6장을 마치며
- collect는 스트림의 요소를 요약 결과로 누적하는 다양한 방법을 인수로 갖는 최종 연산이다.
- Collectors라는 Collector구현체를 통해 다양한 리듀싱 연산을 손쉽게 할 수 있다.
groupingBy, partitioningBy로 스트림의 요소를 그룹화,분할할 수 있다.- 다수준의
그룹화, 분할, 리듀싱 연산에 특화되어있다.
- Collector 인터페이스를 직접 구현해 커스텀 컬렉터를
개발, 기존의 컬렉터를 튜닝할 수 있다.




