발생 현상
- AUIGrid(자바스크립트 라이브러리)를 사용하는 엑셀 다운로드 시 깨진 파일을 다운받음
- 그러나 백엔드 서버에서 해당 파일을 저장해둔 위치에 가서 파일을 열어보면 정상적으로 열리는 상태
- 다운로드 받은 파일(깨진 파일)과 정상 파일을 메모장으로 열어서 데이터 비교했을 때 파일이 쓰이다 만 것처럼 데이터가 들어가 있음(깨진 파일은 데이터가 중간에 끊김)
발생 원인
- 파일이 중간에 깨진 이유는 디스크 쓰기 작업이 완료(flush)되기 전에 파일을 반환했기 때문에 발생
- 백엔드 서버의 로직을 봤을 때 해당 코드는 동기적으로 처리되어야 정상인데 왜 문제가 발생했는가?
- AIP 서버에서 파일 데이터를 수신하면, 해당 데이터는 먼저 메모리에 존재하는 파일 스트림에 저장됨. 이 시점에서 쉘 스크립트는 파일 쓰기 작업이 완료된 것으로 간주(php 코드도 동일)하고, 바로 다음 단계로 넘어간다. 하지만 파일 스트림의 내용이 실제 디스크에 완전히 flush되기 전에 프론트에서 해당 파일을 다운로드받아 문제가 생기고 있었음
- 엑셀 다운로드 흐름
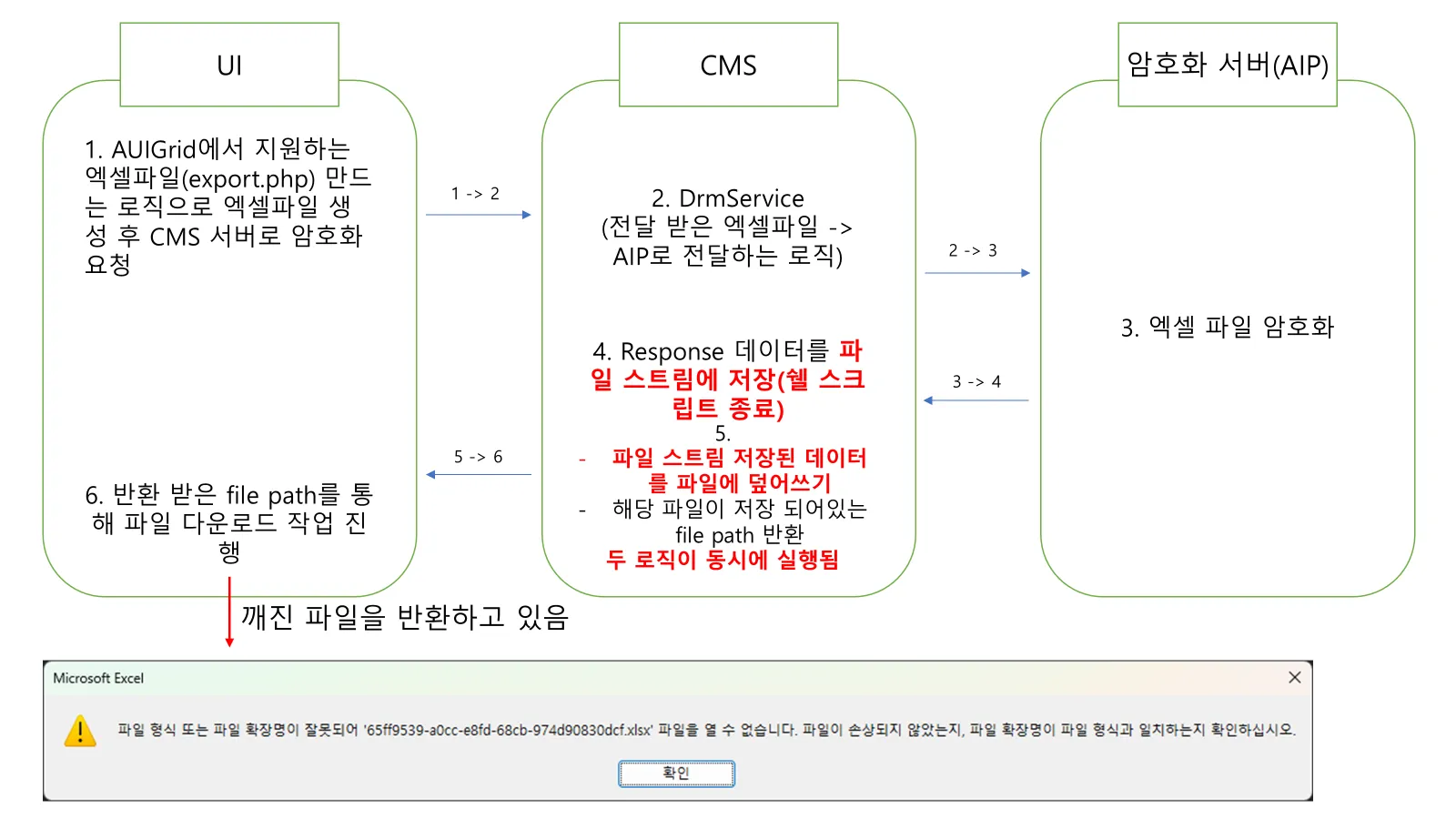

해결 방안
- 3초 딜레이 적용
- AUIGrid에서 사용하는 백엔드 호출 로직(
DrmService.php)에sleep(3)을 추가하여 디스크 flush가 완료되도록 유도
- AUIGrid에서 사용하는 백엔드 호출 로직(
- 쉘 스크립트 내에서 파일 디스크 flush 유도
- mv 명령어 사용 시 OS 스케줄러의 디스크 flush를 유도하는 커널 레벨 특성을 이용
- 반환받은 파일 데이터를
.tmp확장자로 저장한 후,mv file.xlsx.tmp file.xlsl방식으로 이름 변경 처리 - 이 과정을 통해 flush가 완료된 시점에만 최종 파일로 접근 가능하게 만듦
- python flush() 시스템콜 직접 호출
- 아래의 파이썬 호출 코드를 쉘 스크립트 에서 실행
python3 -c "f = open('${ORIGINAL_PATH}', 'rb+'); import os; os.fsync(f.fileno()); f.close()"
- 아래의 파이썬 호출 코드를 쉘 스크립트 에서 실행
고려 사항
- 해당 문제는 운영 환경에서만 발생하며, 개발 환경에서는 재현되지 않기 때문에 정확한 원인 분석이 제한적
- 운영 서버에서 직접 코드를 수정하거나 임시 로직을 삽입해 테스트할 필요가 있음
- 백엔드에서 생성하는 다른 엑셀 암호화 파일들도 같은 문제의 가능성이 존재함
- 다만, 해당 로직은 후처리 과정이 존재하기 때문에 자연스러운 딜레이가 발생해 flush가 완료되고, 문제 없이 다운로드가 가능했던 것으로 보임. 따라서 AIP 암호화 처리시 반드시 호출하는 쉘 스크립트 내에서 해결하는 것이 Best
요약

반응형
'LTF(learn through failure)' 카테고리의 다른 글
| 파일 flush 문제 해결 전략 (1) | 2025.04.13 |
|---|---|
| 파일 flush 문제 공유 (NFS) (0) | 2025.04.13 |