RAFT
클러스터란?
RAFT에 설명하기에 앞서 클러스터 용어의 설명이 선행되어야 합니다. 클러스터(Cluster)는 여러 대의 서버(노드)가 하나의 시스템처럼 동작하도록 구성된 집합체입니다.
이를 통해 시스템은 장애 발생 시에도 서비스를 지속할 수 있는 고가용성(HA) 과 데이터 일관성을 보장할 수 있습니다.
RAFT 란?
RAFT(Raft Consensus Algorithm) 는 분산 시스템에서 여러 노드 간 데이터 일관성과 합의를 유지하기 위한 리더 선출 기반의 합의 알고리즘으로 리더 선출과 로그 복제를 통해 일관성을 확보합니다.
클러스터 내 노드는 리더(Leader)와 팔로워(Follower)로 구분되며, 리더는 주기적으로 하트비트(Heartbeat) 신호를 전송하여 팔로워의 상태를 모니터링하고 클러스터의 정상 동작을 유지합니다.
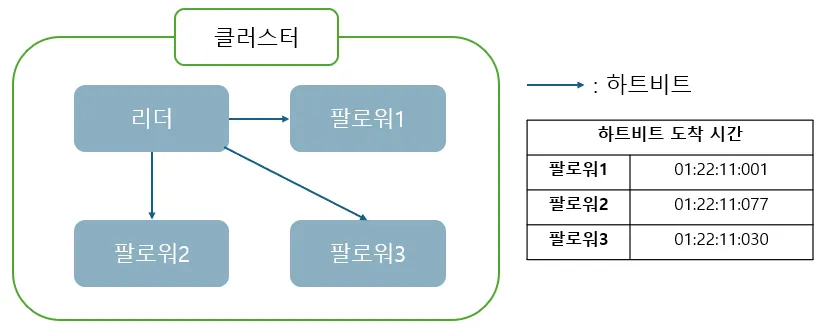
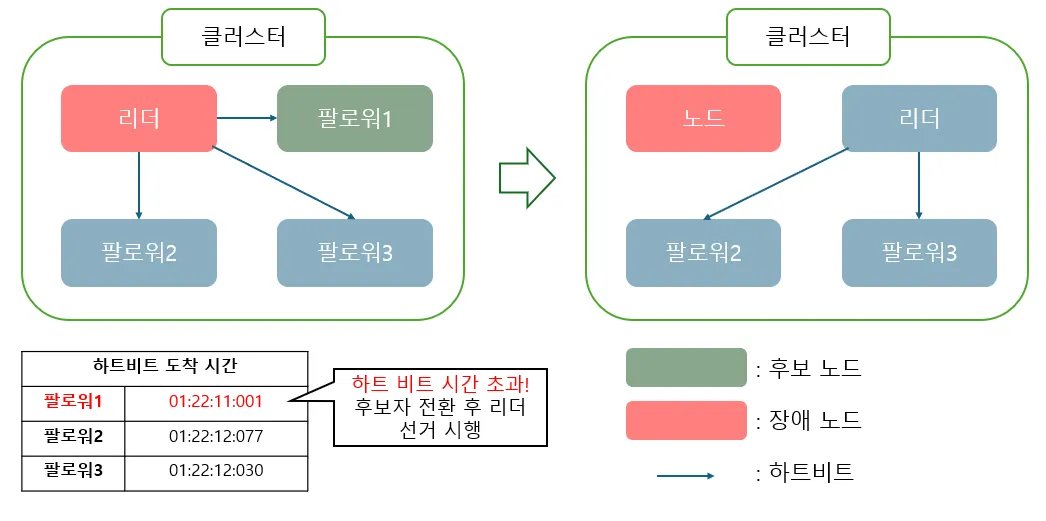
리더 선거
리더는 주기적으로 하트비트를 전송하여 팔로워의 상태를 점검합니다.
팔로워 노드는 리더로부터 일정 시간(ex: 150~300ms) 하트비트 메시지를 받지 못하면 리더 장애로 판단하고, 스스로 후보자(Candidate)로 전환한 뒤 새로운 리더를 선출하는 텀이 시행 됩니다.
텀은 리더 선출하는 임의의 기간으로, 각 후보 노드 중 과반수 표를 받으면 리더 선출이 완료됩니다.
리더 선출이 성공적으로 완료되면 새 리더가 조정하는 정상적인 운영을 진행합니다.
로그 복제
리더는 클라이언트의 요청을 로그 형태로 기록하고, 이를 모든 팔로워에게 복제합니다. 과반수의 팔로워가 로그를 수신·저장했다는 응답을 보내면 리더는 해당 로그를 커밋(Commit) 하며, 커밋된 로그는 모든 노드에 동일하게 적용되어 클러스터의 데이터 일관성을 유지합니다.
RAFT를 왜 사용하는가?
RAFT를 사용하면 다중 환경 시스템에서 클러스터 내의 고가용성을 보장하기 편리하기 때문입니다.
예를 들어 MongoDB의 Replica Set 구조에서는 데이터를 저장할 때 리더에 최초 저장, 이후 팔로워가 리더의 데이터를 참고해서 복제하는 방식으로 동작합니다. 이 때 팔로워는 복제(Replication)되었기 때문에 백업 서버로 활용될 수 있으며, 고가용성(High Availability)을 위한 교체 서버로 활용할 수 있기 때문입니다.
RAFT 합의 알고리즘 실 사용 사례
다양한 곳에서 RAFT 합의 알고리즘을 활용함
- IBM MQ
- MongoDB
- RabbitMQ
- Apache Kafka (KRaft)